

By Yara Bensalem | Updated on March, 2026 | 🕓 14 minutes
Key Highlights
- What makes AI vendor lock-in more expensive than most users expect?
- How do prompts, workflows, and institutional habits quietly become tied to one model ecosystem?
- Why is Human-in-the-Loop (HITL) better understood as a resilience system instead of a quality-control patch?
- What is a “Cognitive Infrastructure Lease,” and how does it affect remote workers and digital nomads?
- How can individuals and small teams build multi-model workflows without enterprise budgets?
- Which parts of an AI workflow should remain vendor-neutral from day one?
- When does building a multi-provider AI system become unnecessary overengineering?
Over the past two years, from digital nomads in Mexico City to independent consultants in Berlin, from remote developers in Bali to content creators in Lisbon, more and more people have realized that once AI services evolve from “occasional tools” into “daily cognitive infrastructure,” dependency on a single provider stops being a technical preference and becomes a hidden consumer trap.
Three Real Global Traps, Three Different Forms of Lock-In
A
A U.S.-based content marketing company tied its entire content-generation workflow to GPT-4 between 2024 and 2025. By the end of 2025, its monthly API bill had stabilized at around $50,000. In early 2026, OpenAI increased the input token price for its flagship GPT-5.2 model from $1.25 to $5.75 — a price jump of more than 360%.
For that company, the increase translated into an additional $90,000 in annual operating costs out of nowhere.
They evaluated migration options. Re-optimizing all prompt engineering for alternative models was estimated to require $200,000 in direct costs and at least three months of business disruption. In the end, they accepted the price increase.
The brutal part of this case is simple: the cost of leaving was higher than the cost of enduring the increase.
That is the classic definition of vendor lock-in — not that you cannot leave, but that leaving becomes too expensive.
B
In early 2026, Zapier surveyed 542 U.S. executives. The results revealed an unsettling optimism bias: nearly 90% of respondents believed they could switch AI vendors within four weeks if necessary, while 41% thought it could be done in under a week.
Real-world data suggested the opposite.
Among companies that had actually attempted a transition, only 42% reported relatively smooth migrations. The remaining 58% experienced outright failure or unexpected complexity.
The problem was not API documentation. The problem was the “temporary” dependencies nobody had mapped:
- undocumented edge cases,
- fine-tuned logic embedded deep inside workflows,
- and organizational habits silently shaped around the behavior of a specific model.
AI consultant Haroon Choudery summarized it bluntly:
“Switching model providers is no longer just an API migration. It’s the migration of context, workflows, and institutional memory. And most operators I meet have never mapped any of those.”
C
If you think these risks apply only to enterprise API users, consider the situation of individual developers.
In April 2026, GitHub Copilot stopped accepting new personal subscriptions, restricted compute resources for existing personal plans, and removed access to Opus models.
For independent developers and freelancers who had built their daily coding workflows around Copilot, it felt as if their trusted “co-pilot” had suddenly taken away part of the steering wheel without warning.
These three cases point toward the same conclusion:
AI vendor lock-in is not a future risk. It is already happening.
It tightens simultaneously across financial, cognitive, and operational dimensions — and individuals or small teams are often more vulnerable than large enterprises.
You do not have a procurement department negotiating SLAs.
You do not have legal teams reviewing policy changes.
You do not have IT departments executing migrations.
The Hidden Lease of Cognitive Infrastructure: A Neglected Framework
Before discussing solutions, I want to introduce a conceptual framework I developed through years of remote work experience:
The Cognitive Infrastructure Lease
When you subscribe to an AI service, you think you are purchasing API calls or compute credits.
In reality, you are leasing three different things.
First: You Lease a Way of Thinking
Every frontier model has its own “personality.”
- Claude prefers structured XML-style prompts.
- Gemini has distinct long-context organizational habits.
- GPT is especially sensitive to system prompts.
When you spend years using only one model, your prompting style, your problem decomposition logic, and even your definition of a “good answer” gradually become synchronized with that model’s characteristics.
That is not just efficiency.
It is a form of cognitive style colonization.
Second: You Lease Your Data Accumulation
Your historical conversations, optimized prompts, and accumulated knowledge bases may feel like personal assets.
But if they exist entirely inside a vendor’s chat interface, they are not fully yours.
Once exported, you often discover:
- broken formatting,
- lost context,
- stripped metadata,
- fragmented organization.
Your knowledge grows roots on someone else’s infrastructure, while the direction of those roots is controlled by someone else.
Third: You Lease Geographic and Policy Resilience
Remote workers often exist in gray zones of service availability.
Between 2024 and 2025, OpenAI significantly increased IP-based risk controls for certain regions. Anthropic repeatedly appeared in policy-related disputes with institutions and governments.
When your core workflow depends on a single provider, you are not only leasing capability — you are also leasing that provider’s:
- policy risks,
- geopolitical assumptions,
- and regional biases.
Understanding this distinction is essential.
We are not discussing “backup plans in case something goes wrong.”
We are discussing whether your cognitive autonomy remains intact.
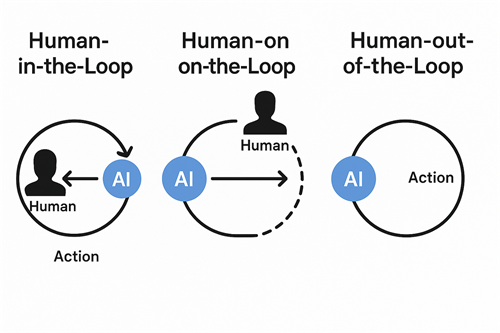
Redefining Human-in-the-Loop: Not an Efficiency Patch, but a Resilience Layer
Traditionally, Human-in-the-Loop (HITL) systems are framed like this:
“AI is imperfect, so humans must supervise it.”
That definition places humans in a passive, corrective role.
I want to propose another interpretation:
HITL as a Circuit Breaker Design
Its purpose is not to add friction while AI functions normally.
Its purpose is to ensure that when the AI ecosystem becomes unstable — through pricing shocks, outages, policy changes, model degradation, or provider restrictions — your cognitive workflow does not collapse instantly.
In other words:
HITL does not primarily exist to compensate for AI stupidity.
It exists to preserve quality assurance during provider transitions.
Based on this understanding, I developed a three-layer resilience model
Layer 1: The Model Layer — Multi-LLM Routing
Create an abstraction layer between applications and models so that changing providers becomes a configuration change instead of an architectural rewrite.
Layer 2: The Review Layer — Humans as Circuit Breakers
Not every step requires manual review.
Human review should activate at points of model disagreement — when two models produce outputs that diverge significantly on the same task.
Layer 3: The Asset Layer — Prompts, Evaluations, and Data Belong to You
Your knowledge assets should exist in vendor-neutral formats.
Providers are temporary executors, not permanent owners.
Practical Framework: A Decentralized AI Workflow for Individuals and Small Teams
The following framework is something I gradually tested over the past two years.
This is not a tool recommendation list.
It is a set of workflow design principles.
Level 1: Prompt Assetization (Prompt as Code)
The biggest anti-pattern is storing carefully refined prompts inside ChatGPT or Claude conversation windows.
This is one of the easiest lock-in points to overlook, and one of the most expensive during migration
My approach is simple:
Manage all production-grade prompts as plain text files — Markdown or YAML — organized by task category:
- content outlines,
- client emails,
- code review,
- data analysis,
- research workflows.
Every task should maintain at least two versions:
- one optimized for stronger frontier models,
- one optimized for fallback models such as open-source or lower-cost APIs.
Why maintain two versions?
Because different models respond radically differently to instruction styles.
- Claude reacts exceptionally well to XML tagging.
- Gemini prefers structured step-by-step guidance.
- Local open-source models usually require more explicit constraints and fewer hidden assumptions.
If you prepare only one prompt system, switching providers means not only replacing API keys, but rebuilding prompt engineering from scratch.
That is exactly how the earlier $200,000 migration cost emerges
Version control does not require enterprise tooling.
A simple Git repository — or even a date-stamped folder structure — is enough to preserve portable prompt assets.
Level 2: Multi-Model Routing (The Model Router)
The core principle is straightforward:
Add an abstraction layer between applications and models.
For individuals and small teams, this does not require enterprise middleware architecture.
Here are three practical implementation paths.
Path A: Unified Command-Line Interfaces
Open-source tools such as `aichat` support unified access across dozens of models.
This works particularly well for terminal-oriented developers and writers.
You can switch backend models within the same command workflow without rewriting prompt logic.
Path B: Visual Workflow Platforms
Self-hostable platforms such as Dify support integrations with more than 100 LLM providers and include:
- RAG pipelines,
- agent orchestration,
- workflow builders.
The key point is not the feature list.
The key point is self-hosting.
Your prompt libraries, chat histories, and knowledge documents remain stored on infrastructure you control.
Path C: Automation Orchestration
Open-source workflow tools such as n8n allow different models to operate inside different workflow nodes.
For example:
- Node 1: lightweight model performs filtering,
- Node 2: stronger model performs deep generation,
- Node 3: separate model performs fact-checking.
This creates true “model chains.”
My routing strategy follows these principles:
- Routine tasks
Formatting, summarization, draft generation
→ prioritize low-cost or open-source models.
- Complex reasoning tasks
Strategy analysis, architecture design, long-context interpretation
→ use frontier closed-source models.
- Sensitive data or offline scenarios
→ use local deployment solutions such as Ollama with Gemma or Qwen models.
Level 3: The Human Review Layer (HITL as Circuit Breaker)
The key idea is not increasing permanent workload.
The key idea is designing trigger conditions.
My distributed three-person team across Asia and Europe uses the following fallback-chain structure:
Primary Model Generates
→ Secondary Model Verifies or Rephrases
→ Low Confidence Triggers Human Review
Specific trigger conditions include:
1. Money, Legal, or Client-Facing Outputs
Regardless of model confidence, humans retain final veto authority.
2. Significant Model Disagreement
When two models produce substantially different conclusions for the same task, that becomes an extremely valuable signal.
It often indicates:
- ambiguity in the task itself,
- incomplete context,
- or hallucination boundaries.
3. Low Confidence Thresholds
This is often implemented through simple consistency testing.
Run the same task twice with different temperature settings.
If outputs diverge excessively, route the task into review.
One underappreciated advantage is that time-zone separation naturally supports asynchronous human-AI collaboration.
Asian time zones handle bulk AI generation and initial filtering.
European time zones later conduct human review and final approval.
This is not efficiency loss.
It is a 24-hour cognitive relay system.
Level 4: Data Sovereignty and Evaluation Harnesses
Your evaluation standards should never be defined by vendors.
I built a vendor-neutral evaluation framework containing three dimensions:
- input completeness,
- expected output alignment,
- quality metrics such as:
- accuracy,
- tone consistency,
- formatting compliance.
The same evaluation framework runs across multiple models.
Before switching providers, you can compare measurable quality metrics instead of relying on vague impressions.
Regarding data storage:
- conversation history,
- RAG knowledge bases,
- fine-tuning datasets,
should remain inside storage systems you control:
- local NAS,
- private cloud infrastructure,
- or at minimum vendor-neutral export formats.
Do not allow your knowledge assets to become merely “user-generated content” inside someone else’s platform.
A Three-Week Minimum Viable Plan
If the framework above makes sense but still feels overwhelming, here is a practical three-week MVP roadmap I personally tested.
Assume you are:
- a content creator,
- an independent consultant,
- or a remote team with fewer than three people.
Week 1: Asset Inventory
Export your most frequently reused conversations.
Not everything.
Only extract prompts that have already matured through repeated refinement.
Organize them by task category.
Then draft at least one fallback-model version for each task.
During this process, you will discover that roughly 30% of prompts heavily depend on vendor-specific behavior — such as Claude Artifacts or GPT Advanced Data Analysis.
Those are your highest lock-in assets.
They should be prioritized for decoupling.
Week 2: Build a Dual-Track System
Choose one Level 2 implementation path.
Connect APIs from two different providers:
- one primary,
- one backup.
At the same time, deploy a lightweight local model.
You do not need expensive hardware.
Consumer-grade laptops can comfortably run smaller Gemma or Qwen models for:
- formatting,
- summarization,
- draft generation.
Week 3: Establish Human-AI Feedback Loops
Choose one high-frequency, low-risk workflow:
- weekly reports,
- content outlines,
- client email drafts.
Then run this chain:
Model A Generates
→ Model B Verifies
→ Human Performs a Five-Minute Final Review
At the same time, create a model disagreement log.
Track tasks where models diverge heavily.
Those tasks identify:
- where humans matter most,
- where ambiguity is highest,
- and where your workflow contains hidden single points of failure.
The Cost Reality Must Be Discussed Honestly
Maintaining multiple vendors plus local deployment usually costs 20%–50% more than relying on a single ChatGPT Plus subscription.
That is not waste.
It is a premium for optionality.
Insurance has never been free.
McKinsey estimated that global AI operational spending in 2026 would exceed $500 billion, representing roughly 300% growth compared with 2024.
Gartner also estimated that poorly optimized AI setups waste as much as 50% of spending on idle compute.
Within that context, paying an additional 20% for redundancy and resilience is actually rational cost management.
An Honest Discussion: When This Is Not Worth Doing
At this point, I need to make an honest counterpoint.
Google’s algorithm changes between 2025 and 2026 increasingly penalized content that only promoted advantages while ignoring limitations.
So here are situations where building a multi-vendor HITL system may not make sense.
If You Only Use AI Occasionally
If you use AI casually for:
- brainstorming,
- quick searches,
- occasional inspiration,
without stable production workflows, then the migration overhead exceeds the benefits.
Building redundancy for a tool used twice a month is like buying full insurance for a bicycle you rarely ride.
If Your Workflow Depends Heavily on Proprietary Features
Some workflows rely deeply on platform-specific capabilities:
- GPT Advanced Data Analysis,
- Claude Artifacts,
- proprietary ecosystem integrations.
If no open alternatives exist, then complete vendor independence is unrealistic in the short term.
If You Cannot Afford the “Resilience Tax”
Maintaining multi-provider systems requires continuous effort:
- monitoring API changes,
- adapting prompts,
- handling multiple billing systems,
- testing compatibility.
This is not a one-time setup.
It is an ongoing cognitive overhead.
My recommendation is simple:
Start with production-grade workflows.
Do not over-engineer casual conversations, brainstorming sessions, or temporary experimentation.
From Consumer Trap to Cognitive Autonomy: A Final Reflection
The deeper meaning of Human-in-the-Loop systems is preserving your muscle memory as a knowledge worker.
If AI suddenly disappears tomorrow, you should still know:
- how to structure a strong content outline,
- how to phrase a client email,
- how to review code critically,
- how to think independently.
That memory should not vanish because a provider changes its pricing, policies, or geography.
For remote workers and digital nomads, this matters even more.
Your workplace has already escaped the office and spread across the world:
- Lisbon,
- Mexico City,
- Bali,
- Berlin.
Do not allow AI providers’ regional restrictions and policy volatility to lock you back inside another kind of digital cage.
Resilience Is a Skill You Can Practice
Turn off your primary AI API for 24 hours.
Force yourself to work using only fallback models plus human review.
You will quickly discover:
- which tasks are genuine cases of AI dependency,
- and which tasks you still fully understand but have simply become accustomed to outsourcing.
That is the only real way to test system resilience.
It is also one of the most effective methods for preventing cognitive atrophy.
The best AI strategy is not making yourself more dependent on AI.
It is ensuring that when you choose not to use AI, you still understand exactly what you are doing.
FAQs
1. What is AI vendor lock-in?
AI vendor lock-in happens when switching providers becomes too expensive, disruptive, or operationally difficult. The lock-in may involve prompt engineering, workflow dependencies, proprietary integrations, stored data, or organizational habits built around one model ecosystem.
2. What is a Human-in-the-Loop (HITL) system?
A Human-in-the-Loop system is a workflow where humans remain part of the decision-making or review process instead of fully delegating tasks to AI systems. In resilient AI workflows, humans act as “circuit breakers” during model disagreements, low-confidence outputs, or provider instability.
3. Why are small teams more vulnerable to AI lock-in than enterprises?
Small teams usually lack:
- procurement departments,
- legal review teams,
- dedicated IT migration support,
- vendor negotiation power.
As a result, sudden API pricing changes, outages, or policy restrictions can create disproportionately large operational risks.
4. What does “Prompt as Code” mean?
“Prompt as Code” refers to managing prompts like software assets instead of temporary chat messages. Prompts are stored in portable formats such as Markdown, YAML, or Git repositories so they can be version-controlled, reused, and adapted across different AI providers.
5. Is using multiple AI providers significantly more expensive?
Usually yes. Maintaining redundancy through multiple providers and local models often costs 20%–50% more than relying on a single subscription or API ecosystem. However, many operators view this additional cost as a resilience premium similar to insurance.
6. Do local open-source models replace frontier AI models completely?
Not usually. Smaller local models are often best suited for:
- formatting,
- summarization,
- low-risk drafting,
- privacy-sensitive tasks,
- offline fallback operations.
More advanced reasoning tasks may still require stronger frontier models.
7. What is a model disagreement trigger?
A model disagreement trigger occurs when two AI systems generate substantially different outputs for the same task. This divergence often signals ambiguity, hallucination risk, incomplete context, or unstable reasoning, making it a useful point for human review.
8. Why is data sovereignty important in AI workflows?
If prompts, conversations, and knowledge bases exist only inside vendor-controlled interfaces, migration becomes difficult and organizational memory becomes fragile. Storing assets in vendor-neutral formats preserves long-term portability and control.
9. Is a multi-provider AI workflow necessary for casual users?
No. Users who only use AI occasionally for brainstorming or quick searches may gain little benefit from complex resilience systems. Multi-provider architectures are most valuable for production-grade workflows that generate income or operational dependency.
References
1. Gartner. (2025). Forecast Analysis: Generative AI Infrastructure and Operational Spending Trends. Gartner Research.
2. McKinsey & Company. (2026). The State of AI 2026: Global Adoption, Spending, and Organizational Impact. McKinsey Global Institute.
3. Zapier. (2026). AI Adoption and Vendor Switching Survey Among U.S. Business Executives. Zapier Research.
4. The Register. (2025). AI Vendor Lock-In Is Becoming the Cloud Era All Over Again. The Register.
5. Anthropic. (2025). Claude Documentation and Long-Context Prompting Practices. Anthropic Technical Documentation.
6. OpenAI. (2025–2026). API Pricing and Platform Documentation Updates. OpenAI Platform Documentation.
7. n8n. (2026). Workflow Automation and AI Orchestration Documentation. n8n Official Docs.
About the Author
Yara Bensalem
Yara Bensalem is an AI systems researcher specializing in human-in-the-loop infrastructure, AI reliability, and operational risk management in automated environments. Her work focuses on the limitations of generative AI systems in real-world deployment, particularly in customer support, enterprise workflows, and large-scale information systems. Yara frequently writes about AI hallucinations, oversight failures, model dependency risks, and the importance of maintaining human accountability within increasingly automated decision-making systems.
Editorial Transparency Statement
This article is independently written and based on publicly available reports, technical documentation, open-source project materials, and industry analysis published between 2024 and 2026.
The author does not receive sponsorships, affiliate compensation, or commercial incentives from any AI provider, infrastructure platform, or workflow tool mentioned in this article.
Examples involving AI vendors, open-source tools, and workflow systems are included strictly for educational and analytical purposes. Tool mentions should not be interpreted as endorsements.
Where possible, the article distinguishes between documented industry data, observed workflow patterns, and the author’s own analytical interpretations.
Disclaimer
This article is intended for informational and educational purposes only and should not be interpreted as legal, financial, cybersecurity, compliance, or enterprise procurement advice.
AI platform pricing, policies, regional availability, and technical capabilities may change over time. Readers should independently verify current documentation, terms of service, compliance requirements, and operational limitations before making infrastructure or business decisions.
The operational strategies discussed in this article may not be appropriate for every organization, workflow, or technical environment. Readers are responsible for evaluating their own risk tolerance, budget constraints, and implementation capacity before adopting multi-provider AI systems or self-hosted infrastructure.